Configurer un flux de conversation

Précédemment
Dans les deux premiers épisodes, nous avons vu comment configurer une base de données structurée et facilement accessible à partir d’une grande quantité de données sous forme de fichiers texte.
Cette base de données nous a permis, dans le deuxième épisode, de construire et de perfectionner un premier modèle de NLP capable de gérer plusieurs domaines liés aux RFQ (Request for Quotes).
Aujourd’hui, nous allons voir comment mettre en place un flux de conversation entre le demandeur et notre intelligence artificielle.
Objectif
Nous avons maintenant un modèle solide, capable d’interpréter efficacement plusieurs intentions différentes. Ce modèle est basé sur des exemples réels, nous sommes donc confiants qu’il n’est pas biaisé et qu’il répondra aux besoins de nos clients.
La prochaine étape consiste à établir des conversations fluides entre nos clients et l’IA. Nous verrons qu’il existe deux philosophies dans ce domaine et nous concentrerons sur le choix que nous avons fait.
Le problème de la gestion des conversations
La conversation est une interaction complexe, c’est pourquoi créer une IA capable de simuler une conversation est si compliqué. Si vous êtes intéressé par les caractéristiques des conversations humaines, vous pouvez consulter cet article académique de l’Université de Stanford : “Chatbots & Dialogue Systems”. Nous résumerons ici la réflexion générale et les points essentiels de notre problème.
L’objectif est de créer un échange fluide entre les différents interlocuteurs. Il est donc nécessaire de dépasser la simple compréhension d’une demande : il faut maintenant mettre cette demande en perspective par rapport aux échanges précédents et même anticiper les échanges futurs.
Nous devons également prendre en compte l’ancrage. L’ancrage est un concept essentiel. Il garantit que le Chatbot comprend progressivement les éléments de la discussion au fur et à mesure qu’ils arrivent.
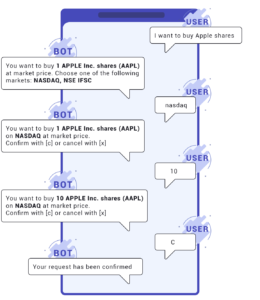
Nous voyons ici que les messages pris séparément n’ont pas de sens. Pourtant, il est naturel pour tout être humain de déduire le sens global d’une conversation à partir d’une séquence de phrases. Nous utilisons notre mémoire immédiate et notre capacité à comprendre les contextes, notamment en connaissant l’interlocuteur et en mettant ses mots en perspective par rapport à ce que nous savons de lui et de ses propos précédents. C’est ce que nous devons fournir à notre IA : une mémoire immédiate et une connaissance du contexte.
Il existe deux approches distinctes pour résoudre ce problème. La première consiste à s’appuyer uniquement sur l’outil NLP pour gérer le flux de conversation. En effet, un Chatbot ne serait pas complet sans un système de gestion de conversation.
La deuxième est d’utiliser une solution « interne », qui peut être adaptée à nos besoins. Pour cela, il sera nécessaire de garder à l’esprit les éléments cruciaux des demandes précédentes et de traiter les suivantes à la lumière de celles-ci.
Motivés par le domaine spécifique de la finance et par le désir d’une gestion spécifique des utilisateurs, nous avons choisi la deuxième solution. Une telle solution nous permet d’adapter le comportement de notre IA à la spécificité des utilisateurs.
Nous présenterons l’architecture que nous avons choisie, ainsi que ses avantages.
Le choix d’une architecture maison
Le choix de mettre en place notre propre architecture était évident dès le début du projet. Ce choix nous a permis d’implémenter une gestion des conversations plus flexible et adaptable, sans rester enfermé dans une interprétation stricte du modèle : il nous a permis d’ajouter de l’intelligence à notre modèle.
Cette architecture nous permet d’ajouter une dimension « profil utilisateur » à notre modèle. Cela nous permet d’ajouter une interprétation à une réponse en tenant compte du domaine d’activité de l’utilisateur et des demandes qu’il est susceptible de faire.
Elle simplifie également la gestion de l’historique des conversations. Stocker une conversation en direct nous permet de gérer le flux de la conversation, mais aussi de créer un historique, ce qui sera extrêmement utile pour faire progresser notre modèle et pour agir rapidement en cas de problèmes.
De plus, ce choix nous a permis de mettre en place une standardisation systématique de nos entités, en utilisant uniquement des données connues, sans laisser de place à l’interprétation.
Voici une présentation de notre architecture simplifiée :
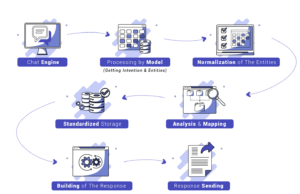
Chaque message envoyé au bot passera par toutes ces étapes. Le message sera d’abord envoyé au modèle NLP, qui l’analysera pour déterminer les entités d’intérêt. Ces entités seront ensuite normalisées, c’est-à-dire transformées en un nombre fini de valeurs prédéfinies. Ces valeurs seront ensuite associées dans un dictionnaire aux attributs correspondants.
Enfin, ces attributs seront stockés dans une base de données qui nous permet de reconstruire les conversations et qui constitue la « mémoire » de notre outil. C’est cette base de données qui nous permettra de mettre en œuvre le concept de conversation et de Grounding.
Nous allons maintenant montrer comment fonctionne notre architecture avec un exemple concret de conversation.
Un flux de conversation concret
Pour cet exemple, nous allons répéter la conversation présentée au début de ce livre blanc. L’utilisateur souhaite acheter des actions Apple. Pour enregistrer sa demande, nous avons besoin de certaines informations :
- Le nom de la société, avec son code court
- Le marché sur lequel acheter
- Le nombre d’actions
- Le prix auquel il souhaite les acheter (par défaut, le prix du marché)
- La quantité (par défaut, une seule)
De plus, comme cet utilisateur est enregistré chez nous, nous savons qu’il est spécialisé dans les marchés américains. Il achètera donc, logiquement, des actions sur les marchés de New York.

Pour un utilisateur donné, la requête initiale sera donc interprétée par le NLP, mais aussi à la lumière de ce que l’on sait de l’utilisateur. Ici, notre utilisateur est manifestement intéressé par l’achat d’actions, nous n’allons donc pas lui proposer d’acheter des matières premières, par exemple.
Cela peut être fait en permettant à l’utilisateur d’accéder uniquement à certaines intentions, ou en vérifiant l’interprétation de notre modèle à la lumière de ce que nous savons de l’utilisateur.
Une fois l’Intention générale de l’utilisateur comprise, nous lui demanderons les informations supplémentaires nécessaires pour exécuter sa demande, dans ce cas, le marché sur lequel il souhaite l’exécuter.
Nous pouvons alors proposer une liste de marchés adaptés à son domaine. Ici, nous voyons que nous n’avons qu’une liste de deux marchés à proposer, ce qui simplifie l’échange.
Notre utilisateur choisit le marché, spécifie la quantité, puis exécute la requête.
Conclusion
Dans ce troisième épisode, nous avons vu comment gérer un flux de conversations, et tous les outils que nous avons mis à son service.
En effet, le choix architectural que nous avons fait nous permet d’ajouter de l’intelligence en plus du NLP pur, notamment en ce qui concerne la gestion des utilisateurs. Il est possible d’imaginer encore plus de rouages qui amélioreront votre IA et vous donneront des atouts pour une meilleure analyse de vos performances, par exemple. Ainsi, une fois qu’une conversation a été enregistrée sur la plateforme de votre choix, vous pouvez imaginer toutes sortes d’outils de surveillance et d’analyse, ou même la création ou l’annotation automatique !
Restez à l’écoute pour la prochaine saison !